Omeka Classic to Omeka S Migration with Decoupled Next.js Frontend
1. Project Overview
This project involved migrating a digital archive from Omeka Classic to Omeka S while fundamentally rearchitecting the system for modern web performance and user experience.
Rather than using Omeka's built-in theming system, I decoupled the frontend and backend—hosting Omeka S on EC2 as a headless CMS and building a custom Next.js frontend deployed on Vercel. This separation enabled:
- Advanced search via Typesense for fast, typo-tolerant queries across thousands of archive items
- Optimized media delivery through S3 and CloudFront for PDFs, images, and large files
- Incremental Static Regeneration (ISR) for fast page loads with automatic cache invalidation
- Modern UX patterns like breadcrumbs, filters, sorting, and social sharing
The system uses Lambda functions for scheduled and on-demand synchronization between Omeka S, Typesense, and the Next.js frontend—ensuring data consistency while maintaining performance.
Live site: https://archive.yourmdl.org
2. Challenge / Problem
The existing Omeka Classic installation faced several limitations:
- Search performance: Built-in search was slow and lacked advanced features like fuzzy matching, faceted filtering, and relevance ranking
- Media delivery: Large PDFs and high-resolution images loaded slowly, especially for users outside the hosting region
- Theming constraints: Omeka's PHP-based theming system made it difficult to implement modern UI patterns and responsive design
- Scalability: Monolithic architecture meant scaling required upgrading the entire server
- Developer experience: Making changes required PHP knowledge and direct server access
Goals:
- Preserve all archive metadata and relationships during migration
- Dramatically improve search speed and relevance
- Optimize media delivery for global audiences
- Enable modern frontend development workflows (TypeScript, React, component libraries)
- Maintain content freshness without manual cache clearing
3. Design Decisions
Why Decouple Frontend and Backend?
Pros:
- Performance: Static generation with ISR provides sub-second page loads
- Flexibility: Full control over UI/UX without Omeka theming constraints
- Scalability: Frontend and backend scale independently
- Developer experience: Modern tooling (TypeScript, React)
- SEO: Server-side rendering with proper meta tags and Open Graph
Cons:
- Complexity: More moving parts to maintain
- Sync overhead: Need to keep Typesense and Next.js cache in sync with Omeka
- Initial build time: More upfront development than using Omeka themes
Trade-off: The performance and UX benefits outweighed the added complexity for a public-facing archive.
Why Typesense Over Omeka's Built-in Search?
Pros:
- Speed: Sub-50ms search queries across thousands of items
- Typo tolerance: Fuzzy matching handles misspellings automatically
- Faceted search: Filter by collection, item type, date range, tags
- Relevance ranking: Configurable ranking based on field weights
- Highlighting: Search term highlighting in results
Cons:
- Additional infrastructure: Requires separate EC2 instance
- Sync complexity: Must keep Typesense in sync with Omeka database
- Cost: Extra server costs compared to built-in search
Alternative considered: Elasticsearch. I chose Typesense for simpler setup, lower resource requirements, and excellent TypeScript support.
Why ISR Over SSG or SSR?
Pros:
- Fast initial load: Pages are pre-rendered at build time
- Fresh content: Pages regenerate in background after 2 weeks
- On-demand updates: Cache invalidation via API when content changes
- Reduced build time: Only changed pages rebuild
Cons:
- Stale content risk: Without cache invalidation, pages could be outdated for 2 weeks
- Complexity: Requires Lambda to trigger revalidation
Trade-off: ISR with cache invalidation provides the best balance of performance and freshness.
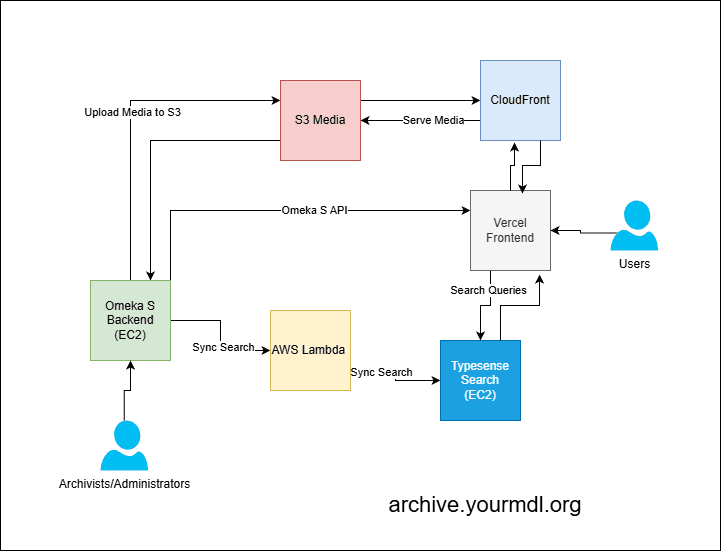
4. Architecture Overview
Core pattern: Headless CMS + Decoupled Frontend + Search Index + Automated Sync
Backend Layer
- Omeka S on EC2: Headless CMS exposing REST API for items, collections, media, and metadata
- Docker Compose: Containerized deployment for Omeka S and MySQL database with volume persistence
- Custom Omeka S modules: Built PHP modules to handle sync webhooks and cache invalidation triggers
- MySQL (Docker): Omeka database with full archive metadata and relationships
- Typesense on EC2: Search engine with indexed archive data
Storage & CDN
- S3: Stores all static assets (PDFs, images, audio, video)
- CloudFront: Global CDN for fast media delivery with edge caching
Sync & Automation
- EventBridge: Scheduled rule triggers sync Lambda
- Sync Lambda (Python): Queries Omeka S API, transforms data, updates Typesense index
- Cache Invalidation Lambda (Node.js): Pings Next.js revalidation API to clear stale pages
- On-demand sync: Admin can trigger manual sync via Omeka S admin panel
Frontend Layer
- Next.js 16 (App Router) with TypeScript
- Vercel: Hosting with automatic deployments on git push
- ISR: 2-week revalidation period with on-demand invalidation
- Typesense client: Direct queries from server components for search results
- Omeka S API client: Fetches detailed item data for individual pages
5. Implementation Highlights
Omeka Classic to Omeka S Migration
The migration process involved:
- Docker Compose setup: Configured containerized Omeka S and MySQL environment with persistent volumes for data and media
- Omeka Classic Importer module: Installed and configured the official Omeka Classic Importer module to handle automated migration
- Data import: Used the Classic Importer to migrate all items, collections, metadata, and relationships while preserving data integrity
- Schema mapping: Mapped Classic metadata fields to Omeka S resource templates during import process
- Media migration: Transferred all files to S3, updated references in Omeka S
- URL redirects: Implemented 301 redirects from old Classic URLs to new Next.js routes
The Classic Importer module handled the heavy lifting of data migration, automatically preserving:
- Item metadata and properties
- Collection hierarchies
- Item-to-collection relationships
- File attachments and media
- Tags and subject headings
- User-generated content
Custom Omeka S Modules
Built two PHP modules for Omeka S:
TypesenseSync Module:
- Hooks into Omeka S events (item created, updated, deleted)
- Sends webhook to Lambda with changed item IDs
- Provides admin UI for manual sync trigger
- Logs sync status and errors to Omeka admin dashboard
CacheInvalidation Module:
- Triggers on content changes
- Calls Lambda function with affected URLs
- Batches invalidation requests to avoid rate limits
- Provides admin UI to clear entire cache
Typesense Index Schema
The Typesense index includes fields for item ID, title, description, collection, item type, creation date, tags, creator, media count, and thumbnail URL. Faceted fields enable filtering by collection, type, date, tags, and creator, with results sorted by creation date by default.
Lambda Sync Function
The Python sync Lambda fetches changed items from the Omeka S API, transforms them to match the Typesense schema, performs batch upserts to the search index, and triggers cache invalidation for affected pages.
Cache Invalidation Lambda
The Node.js invalidation Lambda receives item IDs, generates the affected URLs (item pages, collection pages, and search), and calls the Next.js revalidation API to clear stale cached pages.
Next.js Frontend Features
Item Detail Pages:
- ISR with 2-week revalidation
- Full metadata display with schema.org structured data
- Social sharing button
- Breadcrumb navigation
Navigation & UX:
- Collection browse with grid/list views
- Tag cloud for topic exploration
- Responsive design (mobile-first)
SEO Optimization:
- Server-side rendered meta tags
- Open Graph tags for social sharing
- Sitemap generation
- robots.txt with proper directives
5.1. Screenshots
Search Interface with Typesense
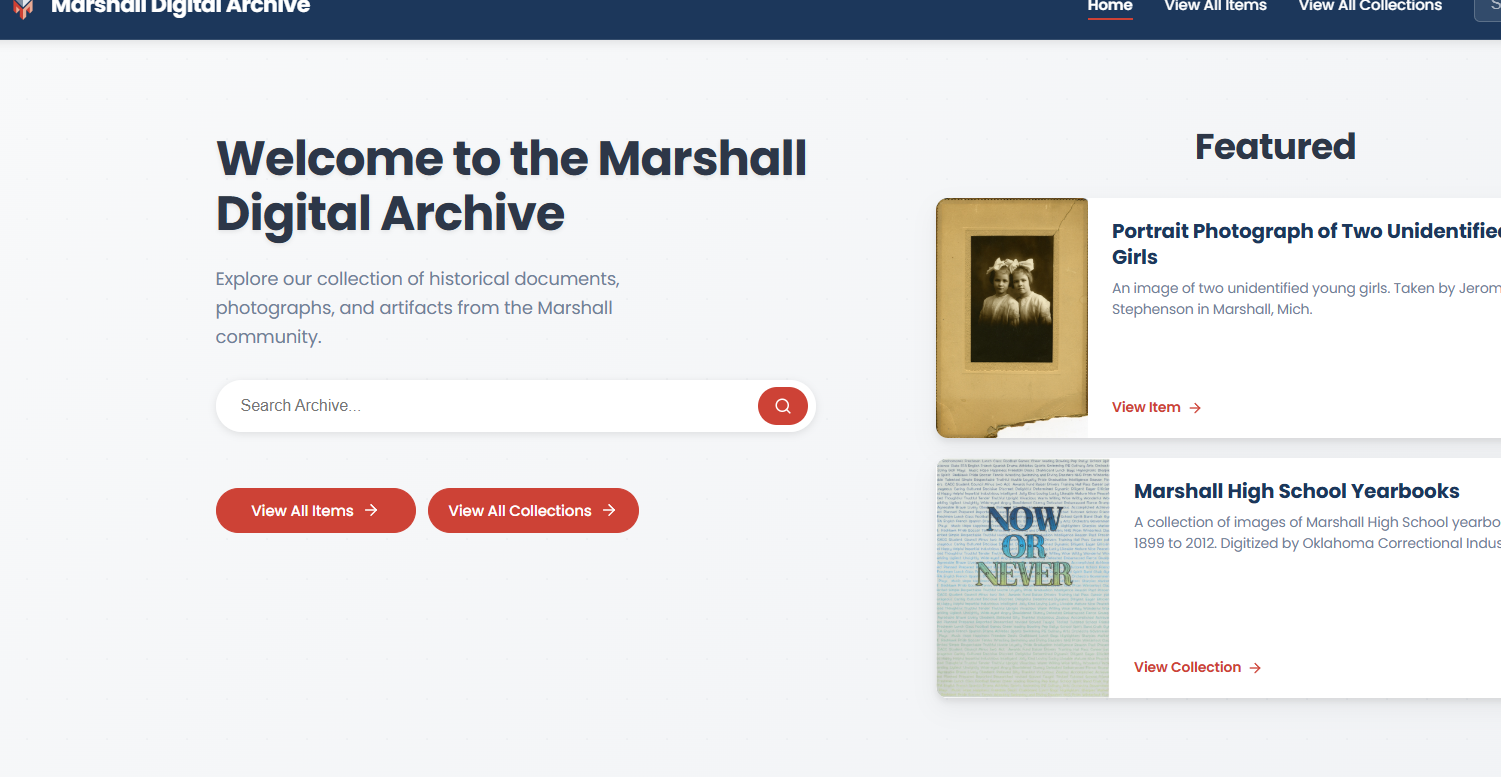 Advanced search with faceted filters, real-time results, and sort options powered by Typesense
Advanced search with faceted filters, real-time results, and sort options powered by Typesense
Item Detail Page
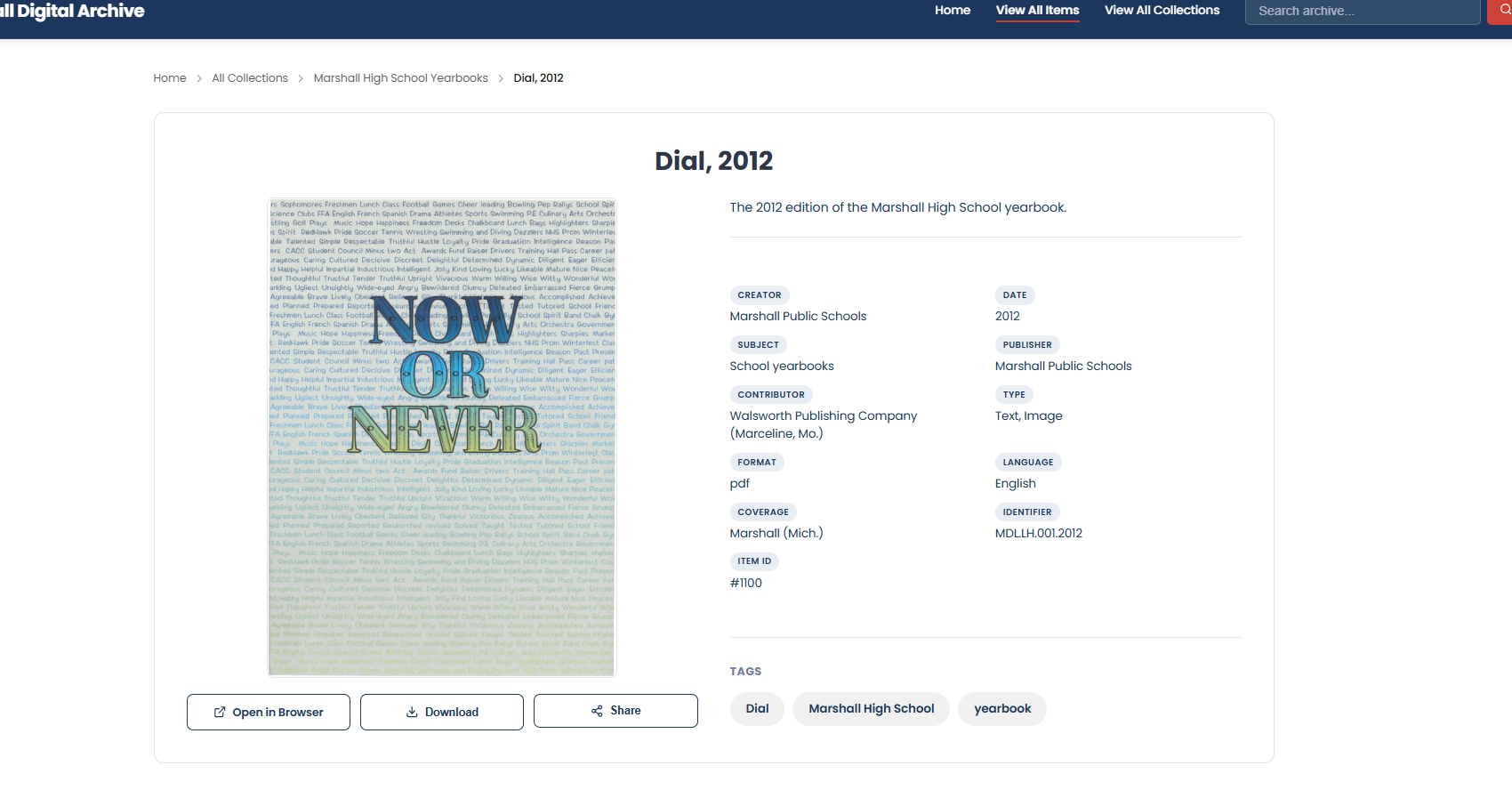 Modern item detail view with full metadata, media viewer, breadcrumb navigation, and social sharing
Modern item detail view with full metadata, media viewer, breadcrumb navigation, and social sharing
Collection Browse
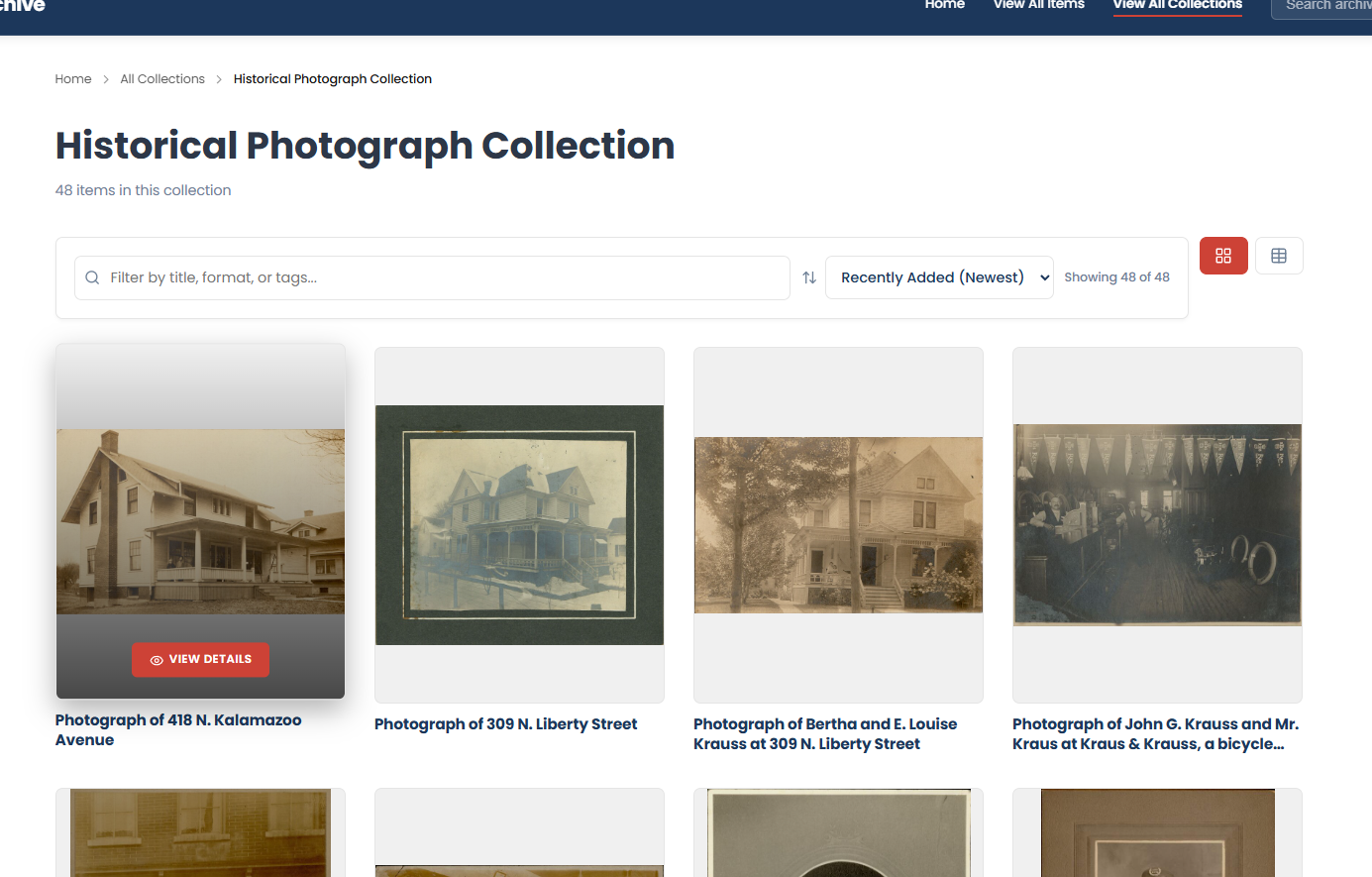 Collection browsing with grid view, thumbnails, and intuitive navigation
Collection browsing with grid view, thumbnails, and intuitive navigation
6. Technical Stack Summary
Backend:
- Omeka S (PHP)
- Docker Compose (containerized deployment)
- MySQL (Docker container)
- EC2 (t4g for both omeka and typesense)
- Custom PHP modules
- Omeka Classic Importer module
Search:
- Typesense (self-hosted on EC2)
- Python sync scripts
Storage & CDN:
- S3
- CloudFront
Automation:
- Lambda (Python + Node.js)
- EventBridge (scheduled rules)
Frontend:
- Next.js 16 (App Router)
- TypeScript
- Vercel (hosting)
Infrastructure:
- AWS (EC2, RDS, S3, CloudFront, Lambda, EventBridge)
- CloudFormation (SAM template)
Conclusion
This project demonstrates how legacy digital archives can be modernized without sacrificing data integrity or institutional knowledge. By decoupling the frontend from Omeka S and leveraging modern web technologies, we achieved:
- Faster search with Typesense
- Faster media delivery with CloudFront
- Faster development with TypeScript and Next.js
- Better uptime with AWS infrastructure
The architecture is designed for scalability (independent frontend/backend scaling), maintainability (TypeScript, infrastructure as code), and extensibility (modular sync system). Most importantly, it provides a modern user experience that makes the archive more accessible and discoverable.
Want to Modernize Your Digital Archive?
If you're running Omeka Classic, DSpace, or another legacy archive system and want to improve performance and user experience, I'd love to help. Whether you need:
- Migration planning and execution
- Decoupled frontend development
- Advanced search implementation
- AWS infrastructure setup
- Performance optimization
Let's connect:
- Book a meeting to discuss your project
- Send me a message with your project details
- View my other projects to see more of my work
💬 Questions about this project?
Get in touch or book a meeting,
or connect with me on 💼 LinkedIn and 🐙 GitHub.